Masters Project
Audio-Driven Head Pose with Deep Learning
Nikolay Nikolov
University College London, September 2020
Supervised by Professor Lourdes Agapito
Abstract
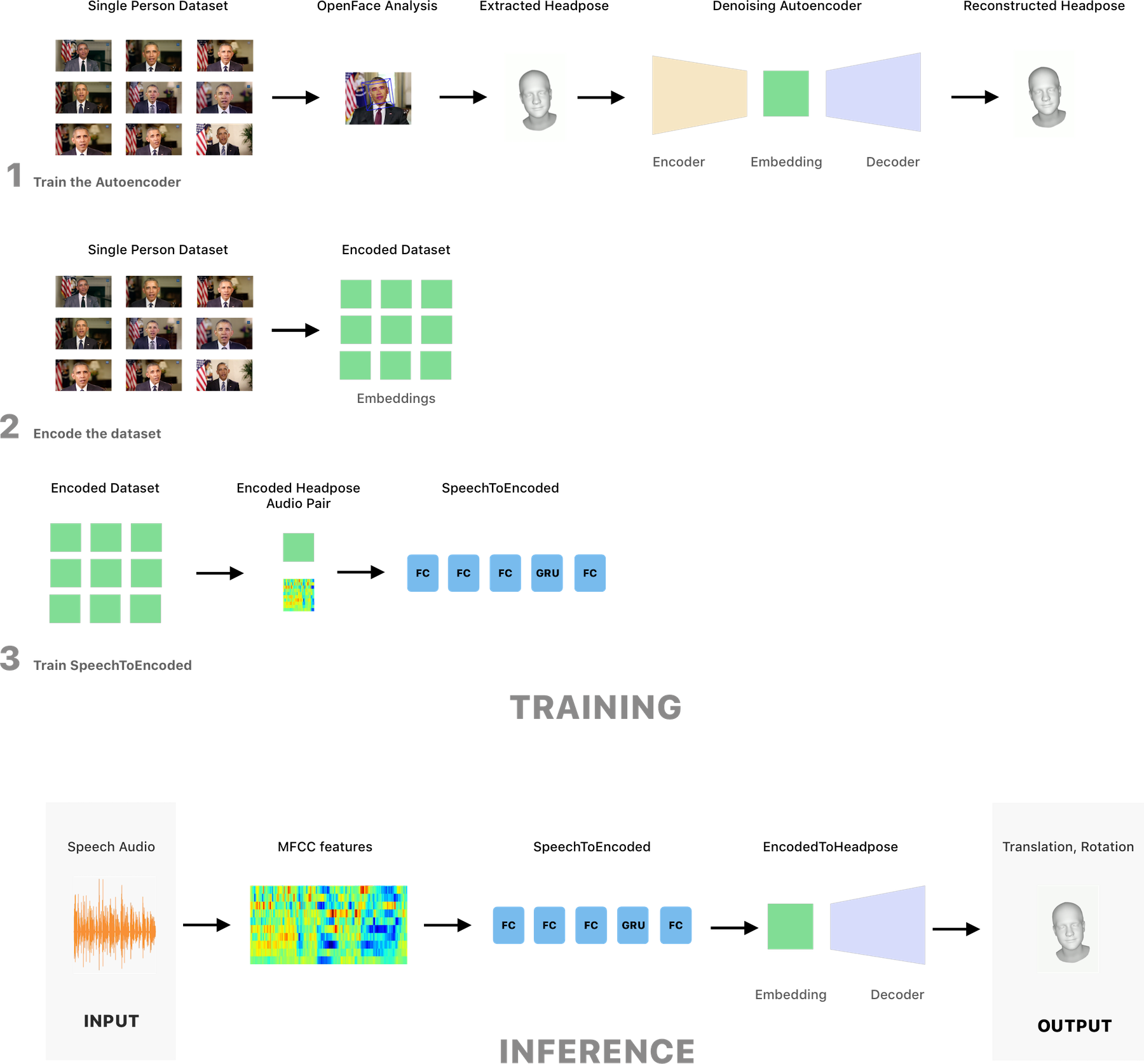
Automatic synthesis of human body motion is becoming an important component of digital media and communications. Currently, this is still a task requiring specialised software and a laborious process. Using audio speech as the driving factor to produce motion data is a desirable option due to the flexibility and availability of speech data. This project focuses on devising a data-driven system using state-of-the-art Deep Learning for mapping audio speech to head pose, made up of a translational and a rotational component.
Data-driven systems require substantial amounts of high-quality curated and pre-processed data to be able to facilitate learning. Thus, a dataset from data in the wild was constructed, by initially scraping online footage of a single source actor, then annotating and analysing it with an off-the-shelf facial analysis tool.
Video
Thesis
Results
Example 1
Example 2
Example 3
Architecture